The problem we were solving
Lab Investigation Reports (LIRs) are high-stakes quality documents — every one must be accurate, consistent, and compliant with global SOPs. Before this tool existed, authors spent significant time drafting, self-reviewing, and correcting reports before they were even ready to be formally reviewed. The process was slow, error-prone, and relied heavily on individual author expertise.
The AI Auditor was designed to change that. The goal: give authors real-time, SOP-aligned feedback as they work — not after the fact — so they could catch issues earlier, reduce rework, and produce consistently higher-quality LIRs.
Scope and scale: We launched the pilot at one North American site and subsequently expanded to four additional sites. The tool also laid the foundation for a broader AI authorship strategy across CAPA, ER, and NCR workflows.
Designing with limited external access
Because this was an internal MVP, we couldn't conduct broad external research before building. Early design decisions were grounded in SME interviews, direct SOP analysis, and tight feedback loops with site teams during the pilot.
The tool also had to operate in a heavily regulated environment, any AI output needed to be clearly framed as assistive (not authoritative), and the design needed to maintain author accountability at every step. This was a compliance requirement.
Starting with the right question
When we received the brief, we didn't jump straight to wireframes. Our first step was to study AI design patterns across similar document-review tools — understanding how they communicate recommendations, structure feedback, and handle the critical question of user trust.
Because the AI Auditor needed to function as a human-in-the-loop assistant — supplementing the author, not replacing their judgment, we built our initial design around two core principles:
The initial home screen was designed with a single, clear primary action: start an audit. We also introduced a percentage-based compliance score to help authors quickly gauge the level of revision their document might need.

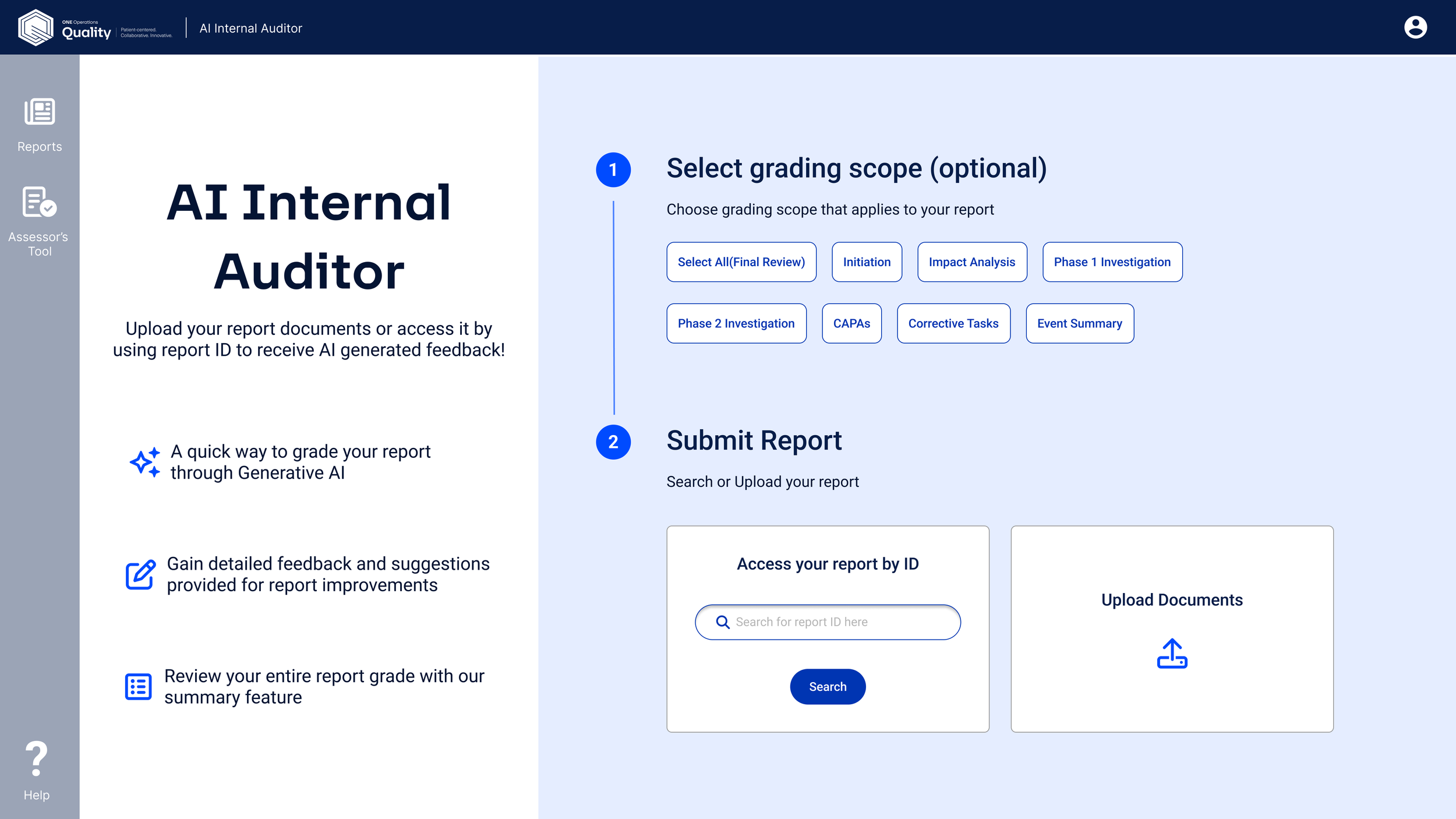
What changed, and why
After the first round of feedback from SMEs, ML engineers, and developers, a few things became clear. Here's how the design evolved:
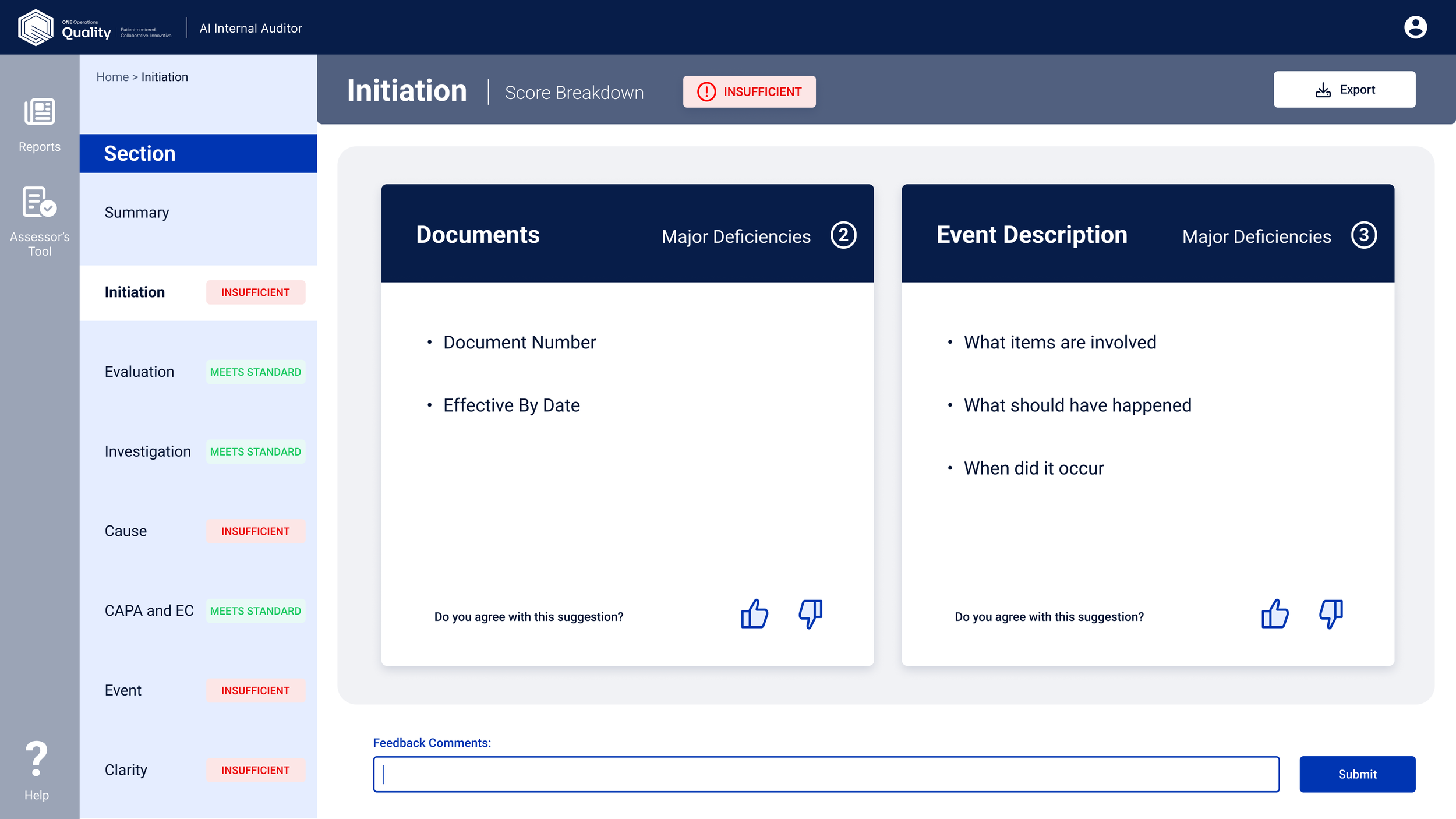
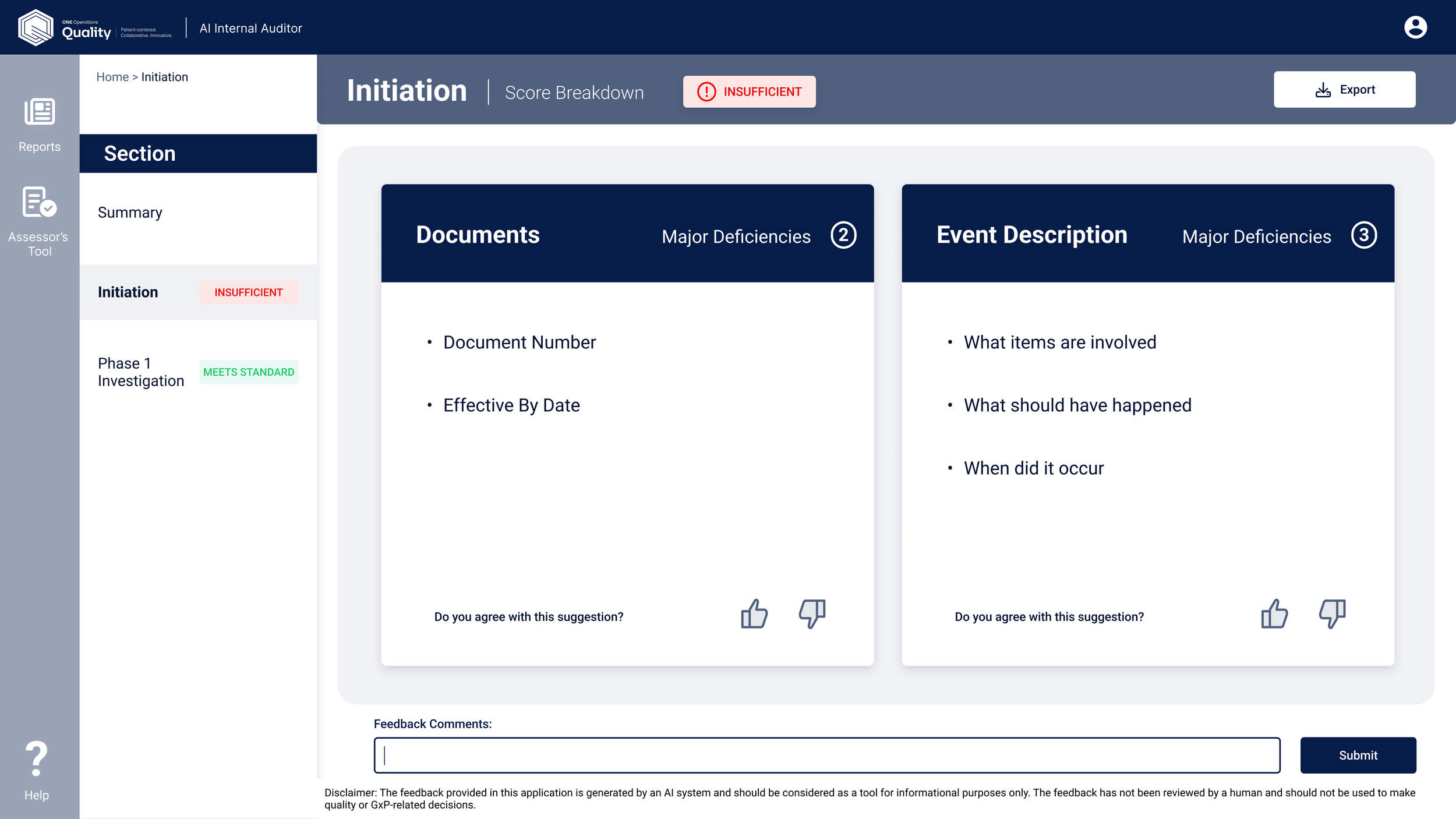
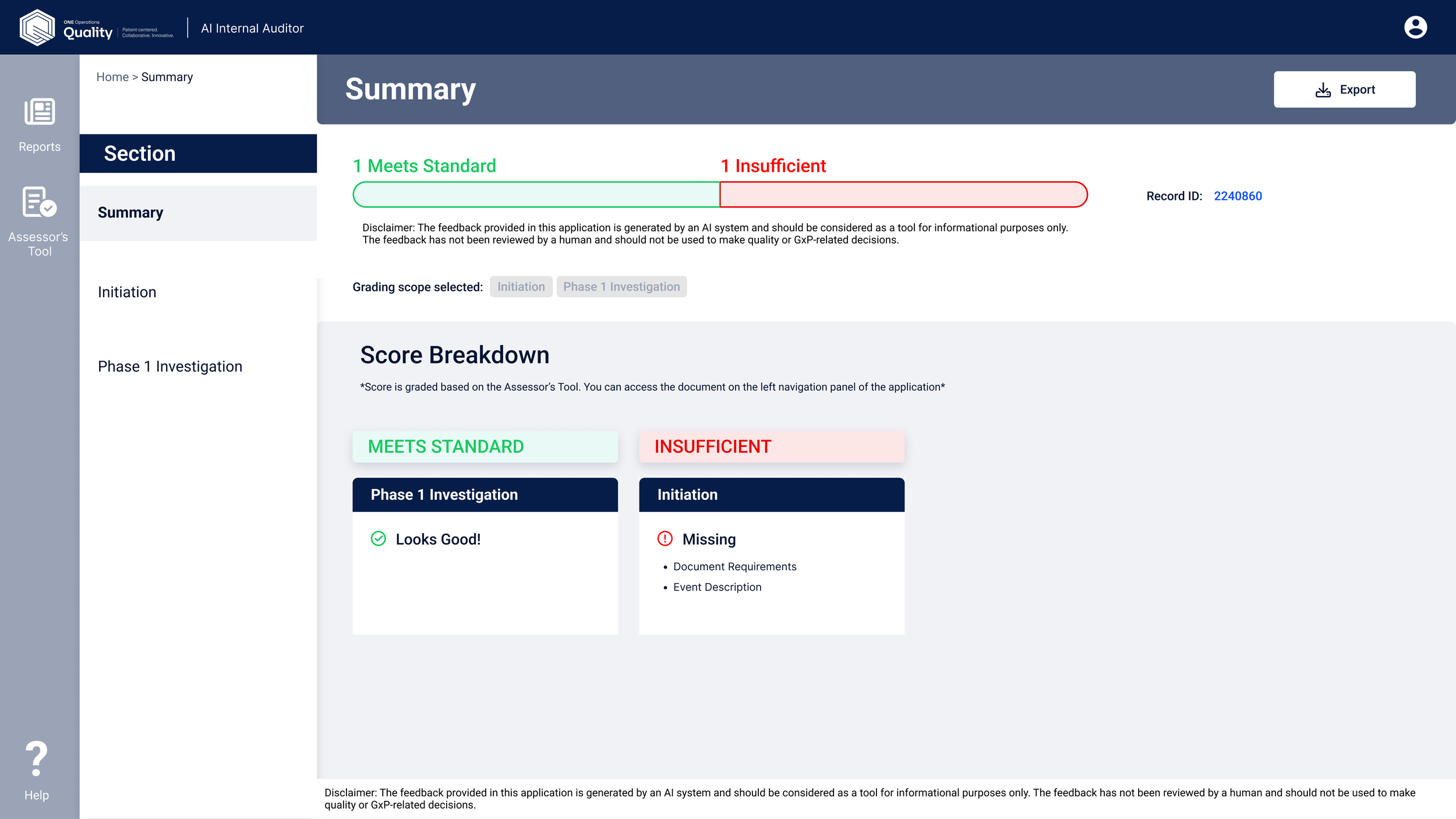
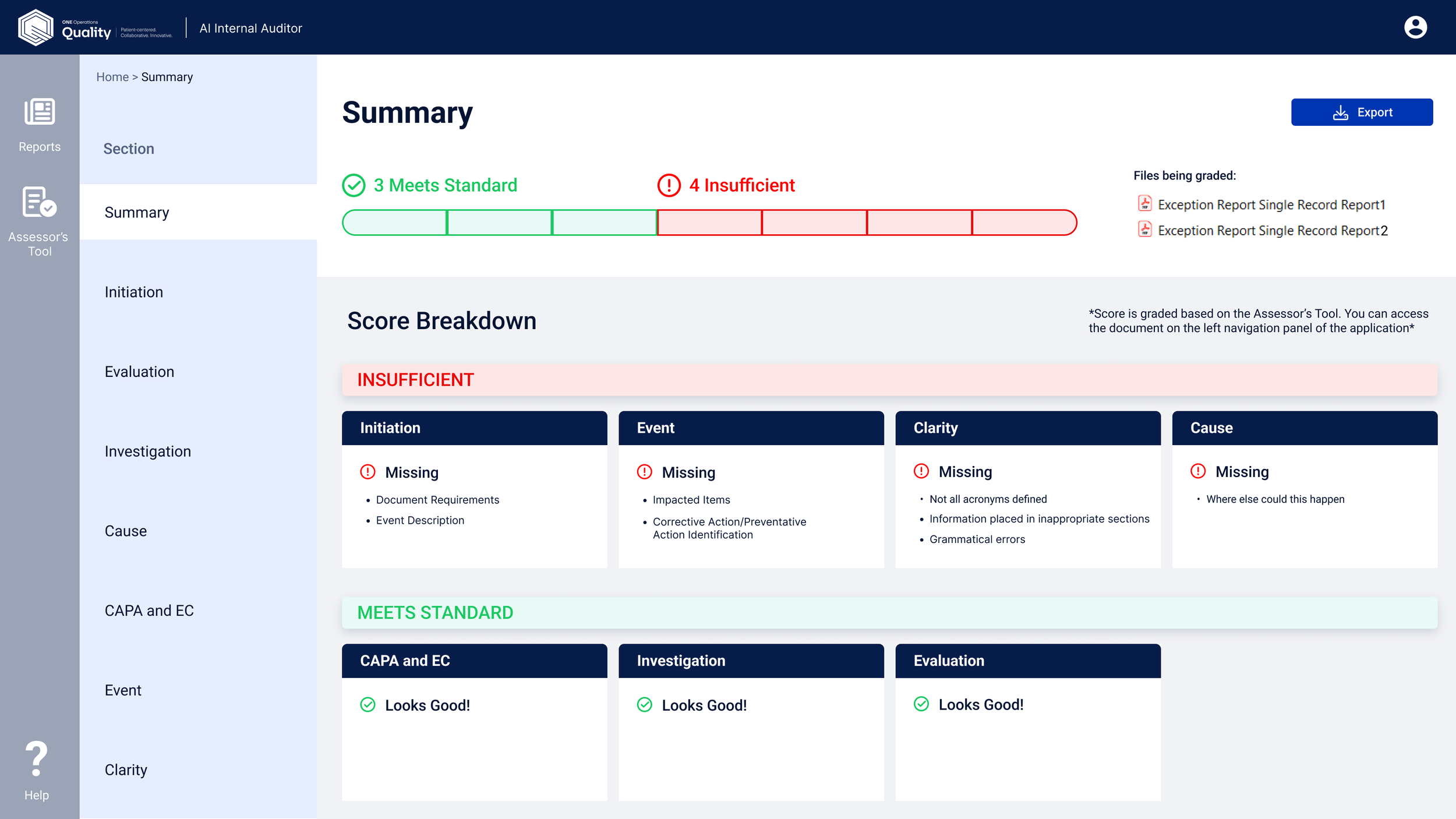
What the tool delivered
Usage grew sharply after the pilot launch, expanding from one site to five as adoption spread geographically. By late Q3 2024, usage was higher and more geographically distributed — confirming strong scalability across diverse teams and contexts.
Quantitative Outcomes
- 80% reduction in LIR review time
- Increased overall LIR quality and SOP compliance
- Reduced time from draft to ready-for-review
- ~30% estimated reduction in manual authoring effort
What the Tool Delivered
- Real-time, SOP-aligned feedback
- Standardized language and structure recommendations
- Clear traceability to regulatory requirements
- Foundation for AI-assisted CAPA, ER, and NCR authoring
Organizational Impact
- Established the first AI authorship pathway at AbbVie
- Scaled to additional languages and products
- Expanded from 1 pilot site to 5 sites across North America
Future Steps
- Broader site rollout
- Formal usability studies post-pilot
- Quality dashboards and analytics
- Standardized templates for CAPA, ER, and NCR workflows